Science dies in chaos: how to keep scientific harmony in the digital era
 The pain of being unorganized
The pain of being unorganizedThe reason I am writing these posts is to give a frame for students and researchers to be organized in their work. Lacking organizational skills will guarantee that you cannot find the files you look for or that you do not understand the code you wrote some time ago anymore. It is unfortunate that these competences are not taught or included in some way in the necessary curriculum across several degrees: whatever we dedicate to through our lives, being organized is key for a successful career. You could of course be chaotic and still be successful, but that would require you to be incredibly intelligent. Since I wanted to cover management skills through the whole scientific process, this is going to be a series of posts. I assume for this that you have some skill in coding (basic bash mainly) and you know your way around a computer.
I would recommend all readers to explore the several packages and resources that I cover here, which can increase your productivity and achieve the philosophy of “working less and thinking more”. Of course, there are many alternatives out there and more often than not, choice is based in taste rather than in fundamental differences. Here are some of the resources I use in my day to day:
The Johnny Decimal system for organizing files and folders. The webpage goes further in depth on managing your projects as well as ways to keep your communication channels portable and transparent. I find this way of organizing my folders extremely organized, which makes transparency, reproducibility and portability realities not ideal abstracts.
The Obsidian note taking app. This has been without a doubt one of the best discoveries I have made, unfortunately, in the last couple of years (if only had I known it earlier). The power of this application resides on the great amount of developers who increase its usability with awesome plugins, as well as good YouTube channels offering tutorials in basic and advanced use. Some exemplary channels are Linking your thinking by Nick Milo and the Bryan Jenks channel. There are some more and I am sure that they are good, but these two are the ones I started with.
Zotero your literature manager and research assistant. I used to use Mendeley as it seemed easier to deal with. I grew disenchanted with it as I find it very restrictive. Zotero, in a similar fashion with Obsidian, has a lot of flexibility and several plugins exist that can enhance your work and the way you obtain knowledge from the literature. I also got to learn that is quite easy to use as well. The screenshot below illustrates my zotero and the different plugins I use for organizing tags and get the number of citations each paper has gotten so far. I hope at some point the dark theme allows for a gruvbox color scheme …:

- The British Ecological Society better guides for science. I would recommend every early career to have a read at these guides, which are written in a familiar language and contain key aspects that you should master for a successful and satisfactory life in academia.
Organizing your files in a smart manner
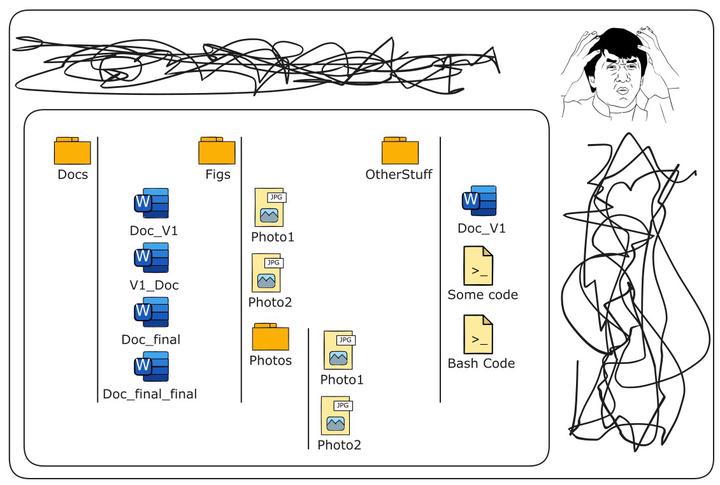
Let me describe a bit the situation in the featured image (at the beginning of this post): this is an exaggerated image of what a chaotic system for organizing files looks like. You see that names can be misleading since there is no way to tell, for example, which word document is actually version 1; files with the same name can be found in different folders and this may not mean necessarily that they are the same file; in general, you can see that there is no consistency, a system is lacking. Now I want you to compare that image with the following.

Now, I am not including file names in that figure, but I will cover that below. The illustration represents a file organization scheme following the Johnny Decimal system. In essence, it consists on storing files in groups of ten up to three levels deep. For example, you can see the first level containing the folders “10-19_Data”, “20-29_Coding”, “30-39_Figures” and “40-49_Documents”; the second level contain folders such as “10_Sampling” and “40_Articles”; and the third level includes folders such as “21.01_Packages” and “31.02_Barplot”. You can quickly observe that I have not reached ten folders in any of the different levels, but you should keep the rule that no level should have a size higher than ten folders. There is one folder I have omitted in the figure for the first level, 00-09. I often use such a folder, for example, to store the funding options for my project as well as the administration and paperwork (invoices, permits, etc). The system facilitates finding files and it is easy to communicate where files are just using the number index, e.g. 19870220_WhiteShark-Malta.jpg is in 30.01.
Naming files
I will start this with something that I find irritating: do not include spaces on a file name nor special letters. Why no spaces? because not all coding languages like spaces, instead you should use underscores “_” or dashes “-”. You have alternatives to this: camelCase.pdf or PascalCase.pdf (you can also use combinations). The same applies to special letters like some that you can find in Scandinavian languages. These are just not portable across different computers. As an apart note, I would ask you to be considerate with your collaborators and use a language you all understand, currently in science, said language is English. Sending files to someone in a language he/she does not understand may not be done in bad conscience, but is not very kind. There is no universal rule about how to name your files but whichever rules you create make sure they describe the file well and briefly and that they are applied always. Here are some examples of good names for files:
- 20220120_Survey12_StationCoords.csv
- 20220205_MakoShark_BiscayBay.jpg
- 03_GamModel_Lengths.R
And here are some bad ones:
- dataset lengths.csv
- code 002.R
- _manuscript_V4.docx
Some suggestions: always use the international standard for date YYYYMMDD (I have to say, Americans get it wrong, their format is ambiguous); decide to follow different rules depending on the kind of file, you may want to call your scripts in a different manner than your raw data files. Finally, do not use the same name for several different files as this creates ambiguity.
Having an already ongoing project without system
Changing paths in scripts
At such stage you must have several scripts that include paths to files. If you relocate your files into new folders, these will not work. Here I show an easy trick to use to correct it. If you have good coding practices (I will cover those in another post), it should not be very time consuming to migrate from your original system to a more organized one. If your skills are not good enough, it may take longer, but I would say it is still worth it. I have done this migration twice this year and it did not take more than one day. The first thing would be to create the folders where you want to store your files (following a Johny Decimal system). The second step would be to move all the files from the original system to the new system you just created. The third step, the more troublesome, would be to correct your scripting and whatever linkage you had between your files that depended on their relative or absolute paths. For this, you first need to get to the root of your project, using the “cd” (change directory) command in your terminal. If you have a linux or mac computer (if you have a windows you could install the software gitbash), you probably have the “find” command. With this command you can get the new relative path where you stored the file. The syntax for the find command is:
find ./ -name "20220210_Metadata_Inds.csv"Where ./ points to the current directory where you are, -name is a flag indicating that the following (20220210_Metadata_Inds.csv) is the name of the file you are looking for (here is a good case to talk about the issue with spaces- if you used spaces in your naming, then you always need to quote the file name). Running that command will return all paths where a file with that name is located (there should only be one). All you have to do in your scripts is to change the old paths with the new paths you obtain in the terminal, so it is a copy-paste exercise.
Renaming files
Renaming files can be more troublesome but terminal coding can facilitate the task a lot. Here are some examples you may use to rename your files:
Change the extension of multiple files In this example all files with the extension .log are changed to have a .txt extension.
for i in *.log; do mv -- "$i" "${i%.log}.txt"; doneAdd a prefix to multiple files In this example, we can add the same date 20220615- to all files.
for i in *; do mv -- "$i" "20220615-$i"; doneRemove a string from multiple files Here we are removing the string “fast-” using the sed command from all files with the extension bam.
for file in *.bam; do
echo "Old file: $file"
new=$(echo "$file" | sed 's/fast\-//')
echo "New file: $new"
doneThese are just some handy examples that I have stored among my notes, but with enough expertise in bash, you could change names in any given circumstance.